Many teams start their AI integrations the same way — one giant system prompt that tries to cover every scenario. It works fine for prototypes. But as soon as you add branching logic, specialised behaviors, or versioning, that single prompt becomes a liability.
The fix is simple but powerful: config-driven architecture.
The Problem with the “One Prompt to Rule Them All” Approach
Devs quickly discover that packing logic into a system prompt is like trying to squeeze an elephant into a cup. You can describe logic in natural language (“If user says X, do Y”), but the model doesn’t execute logic — it interprets it.
That means:
- Results vary. It behaves like a child and only listens sometimes.
- Debugging is a nightmare (expect major inconsistencies).
- Versioning one section breaks another (you fine tune a branch and this screws all prior tests).
- Even if you end up with something working you end up with a 2,000-token packed to the rim which nobody wants to touch.
The model is great at reasoning (assuming you’re not being too cheap) and language — not control flow. So stop forcing it to act like code. It’s not code ( even if you add pseudo code and markdown) it is not code. Trying to make it behave that way is asking for trouble.
Config-Driven Architecture in AI apps
A config-driven approach separates logic (deterministic) from reasoning (probabilistic). You define reusable building blocks — global rules, branch prompts, and schemas — and dynamically compose them at runtime.
Your prompts become data, not hard-coded strings.
Here’s the high-level pattern:
-
Global system prompt
Defines tone, priorities, safety, and behaviour that apply everywhere. Leave the logic out and stay sane. -
Branch-specific overlays
Each function or “mini-app” (returns advisor, marketing writer, data auditor, etc.) has its own prompt overlay with rules and context. -
Prompt registry (config)
All prompts, versions, and output schemas are stored in a simple YAML or JSON config, versioned alongside your code. -
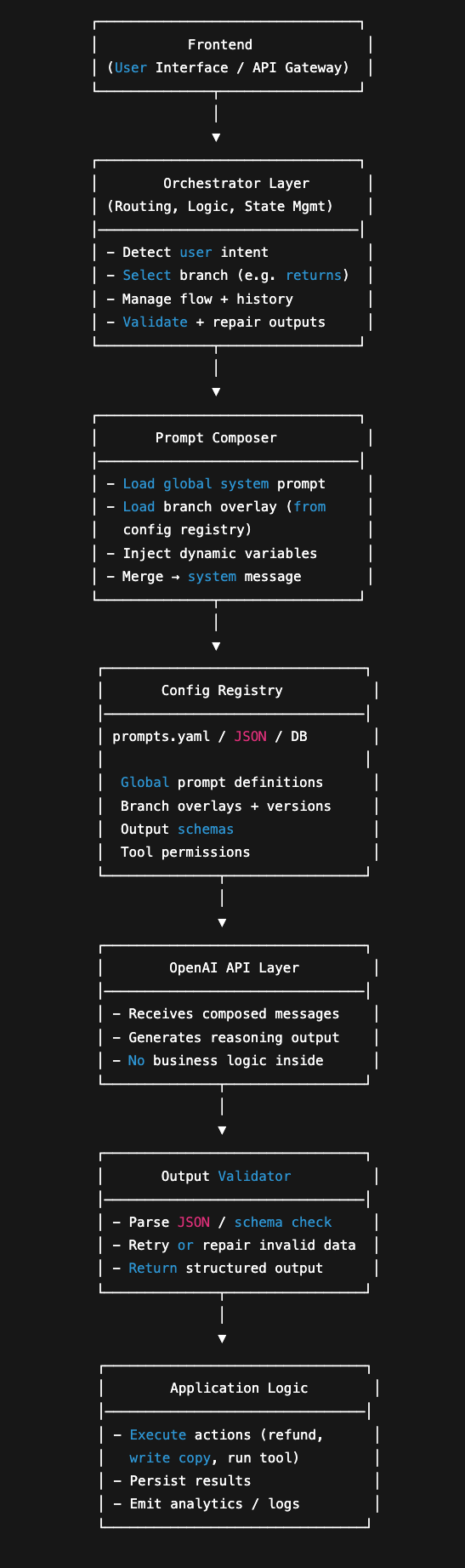
Composer & router
Your orchestrator picks the correct branch based on user intent, merges global + branch + dynamic variables, and sends that to the API. -
Schema validation & repair loop
You enforce deterministic output with JSON schemas or structured outputs. The app validates and, if necessary, re-prompts the model to repair invalid output.
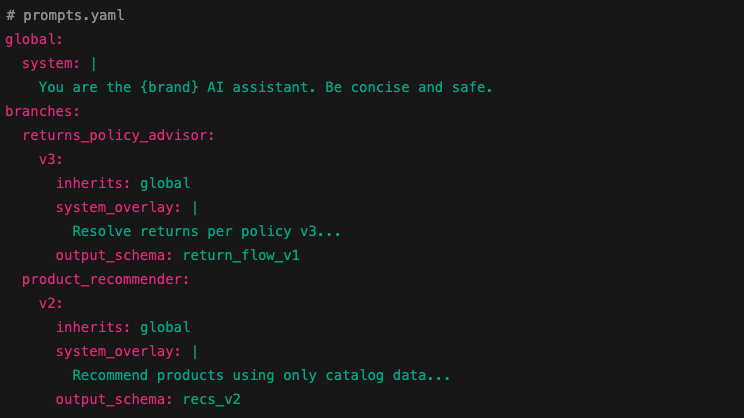
Your orchestrator loads the branch, composes the system message, adds the user message, and handles logic externally. No prompt spaghetti, no conditional English.
Why This Works
Predictability
Logic and routing live in code, not in fuzzy language. The model’s only job is reasoning.
Modularity
Each branch is isolated. Update the returns logic without touching the product recommender.
Versioning & Testing
Branches get version IDs (returns/v3). You can A/B test or roll back instantly.
Maintainability
Non-devs can tweak behaviour in config files — no code deploy needed.
Evaluations
Each branch can have its own eval suite and golden dataset. You can measure improvements instead of guessing.
Practical Tips
-
Keep your global system prompt under ~200 tokens.
-
Include clear output schemas and enforce them in code.
-
Store prompts and schemas in your repo, not scattered across codebases.
-
Log prompt hashes, schema versions, and results for reproducibility.
-
Never let the model decide routing or tool use — that’s your job.

The Bottom Line
Config-driven prompt architecture gives you control without losing flexibility. It also gives you sanity.
It turns prompt chaos into a structured, versionable system that scales from MVP to enterprise-grade orchestration.
If you’re building anything beyond a toy chatbot, this is the architecture you’ll end up with anyway. You might as well start there.
If you need help with ai development services reach out to our team. Use Streamline to speed that process up.